
Encodings Confuse Me
Context
Recently I was learning about the bittorrent protocol from this excellent video series on youtube. The creator of the series Arpit Bhayani explaines all about the protocol, the seeders, the leechers, decentralized (the usual). Then he explained what a .torrent file was. A .torrent file has a bunch of fields to get the file names, file lenghts, the url to find the tracker where your torrent is listed. These files are bencoded (or the files are bencoded encoded? idk). He suggested that it was a good idea to write your own decoder for bencoded files.
And so I did…
When you open a .torrent file in an editor such as notepad, this is what you are presented with.
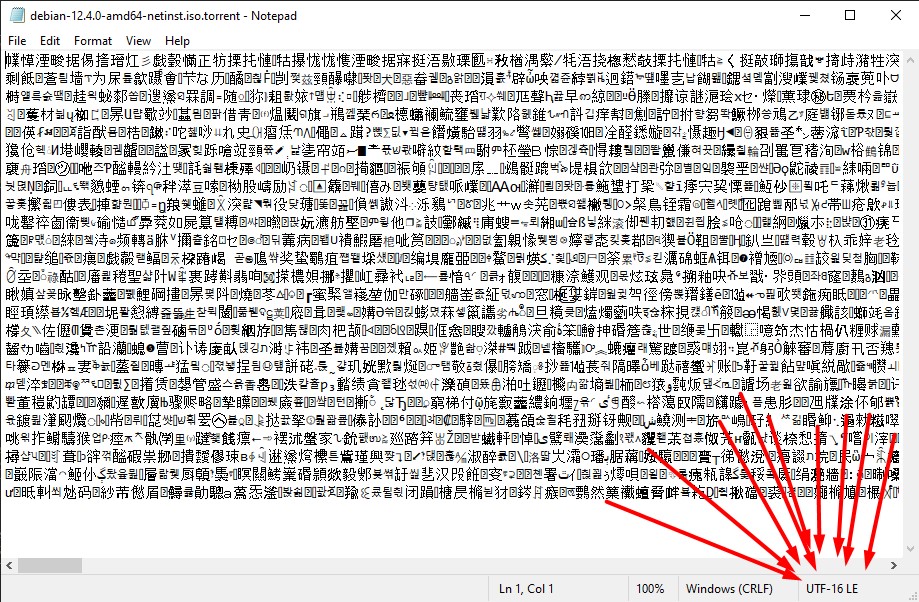
What???
There must be something wrong with this file. How could a computer ever read this gibberish. Then I saw it in the corner (Arrows 😉) UTF-16 LE
wikipedia: “UTF-16 (16-bit Unicode Transformation Format) is a character encoding capable of encoding all 1,112,064 valid code points of Unicode (in fact this number of code points is dictated by the design of UTF-16). The encoding is variable-length, as code points are encoded with one or two 16-bit code units.”
Huh.. The file is UTF-16 LE encoded? But I thought these files were bencoded.

Well no, the file is neither UTF-16 LE encoded or bencoded. Let me explain…
Basically all files on a computer are stored as a series of bits. There is no exception to this. Thus a .torrent file is also stored in only one’s and zero’s. Then why doesn’t notepad show that? Is it possible to just see the bits of the file like this?

Yes it is, but no one does that. We use hex encoding for that. (there it is again, that word. encoding… 🤨) Let’s visualize our .torrent file with a hexdump tool. This is possible with a plugin in Notepad++.

What you see here are the first 160 bytes of the file (16 bytes per row x 10 rows). Hexadecimal is a great way to represent binary, because every hexadecimal character represents a nibble (4 bits) and 2 characters represent a byte (8 bits). You could say that hexadecimal is an encoding of binary, to make binary more easily readible.
Encodings are like contracts. It tells you what a sequence of bits mean. We have many contracts that tell you what a sequence of bits mean. The table below show the following 45 bytes decoded using different text decoding contracts.
54 68 65 20 71 75 69 63 6b 20 62 72 6f 77 6e 20 f0 9f a6 8a 20 6a 75 6d 70 73 20 6f 76 65 72 20 31 33 20 6c 61 7a 79 20 f0 9f 90 b6 2e
| encoding | decoded |
|---|---|
| UTF-8 | The quick brown 🦊 jumps over 13 lazy 🐶. |
| UTF-16 | 桔畱捩牢睯鿰誦樠浵獰漠敶㌱氠穡⁹鿰뚐� |
| Big5 | The quick brown �� jumps over 13 lazy �濶. |
UTF-16 and Big5 doesn’t really seem quite right huh? They still output legible text, but it doesn’t seem logical to us. That’s because the writer of the sentence had encoded that sentence in UTF-8.
Remember those weird Chinese characters in my .torrent file? Well that was because our program assumed the file was encoded with the UTF-16 contract. However the specifications for .torrent files tell us that it is encoded in UTF-8. Let’s try that.

That looks better!
What we have learned untill now:
- all data is stored as bytes
- Humans need to know what the bytes mean. The translation rules from bytes to text is called an encoding
What we still want to know: How does bencoding come in to play?
The text in te .torrent file is supposed to represent a dictionary of key-value pairs.
Does this look like a dictionary to you?
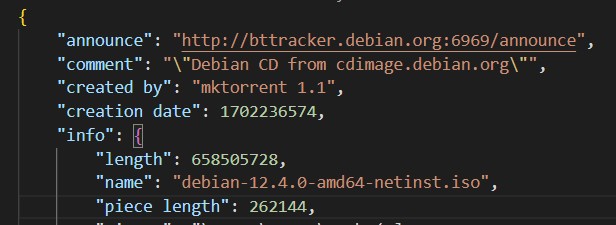
d8:announce41:http://bttracker.debian.org:6969/announce7:comment35:“Debian CD from cdimage.debian.org"10:created by13:mktorrent 1.113:creation datei1702236574e4:infod6:lengthi658505728e4:name31:debian-12.4.0-amd64-netinst.iso12:piece lengthi262144e6:pieces50240:
No?
To me either, but it is. You just don’t know the rules man… 😉

Just like we decoded binary giberish into legible text using UTF-8, we can decode this giberisch text into a dictionary following the rules of bencoding. That is exactly what I have done in this Python script.
Using the rules of bencoding, we can decode our .torrent file and write it out into a json file.
Conclusion
I get it, all those different encodings floating around can be confusing. From UTF-8 to ASCII, they all seem to do similar things, converting stuff between text and binary. Then there’s bencoding for torrent files, which is like a special way to turn text into a dictionary. It’s kind of cool once you realize that all these encodings are just different ways to handle data conversions.